
使用目标检测模型yolov5制作ai自瞄外g(上)
环境搭建
教程视频,这里附上育婴级视频链接
【手把手带你实战YOLOv5-入门篇】YOLOv5 环境安装(重置版)哔哩哔哩_bilibili
1.Miniconda安装
miniconda是anaconda虚拟环境的一个简易分支,比较轻便,使用国内清华源下载
1 | https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/ |
安装后终端输入以下代码创建虚拟环境
1 | conda create -n yolov5 python=3.8 |
2.pypi镜像设置
1 | https://mirrors.tuna.tsinghua.edu.cn/help/pypi/ |
在虚拟环境输入以下代码换源
1 | pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple |
3.Pytorch
1 | https://pytorch.org/ |
我的电脑是3060,显卡驱动版本信息和cuda最大支持版本信息如下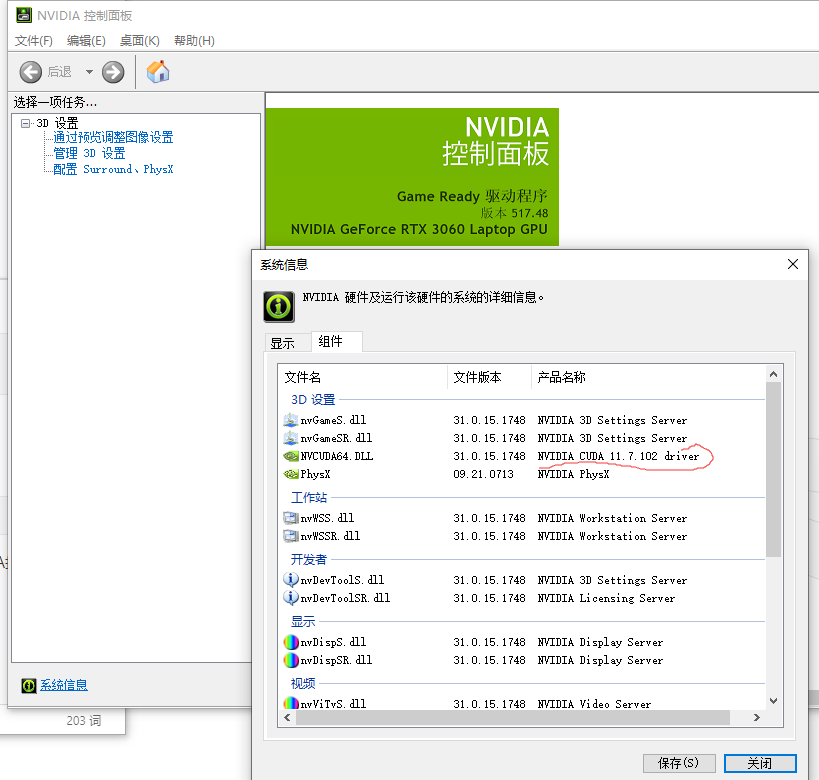
在虚拟环境使用如下命令
1 | pip3 install torch==1.8.2 torchvision==0.9.2 torchaudio==0.8.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cu111 |
测试pytorch安装和gpu调用是否成功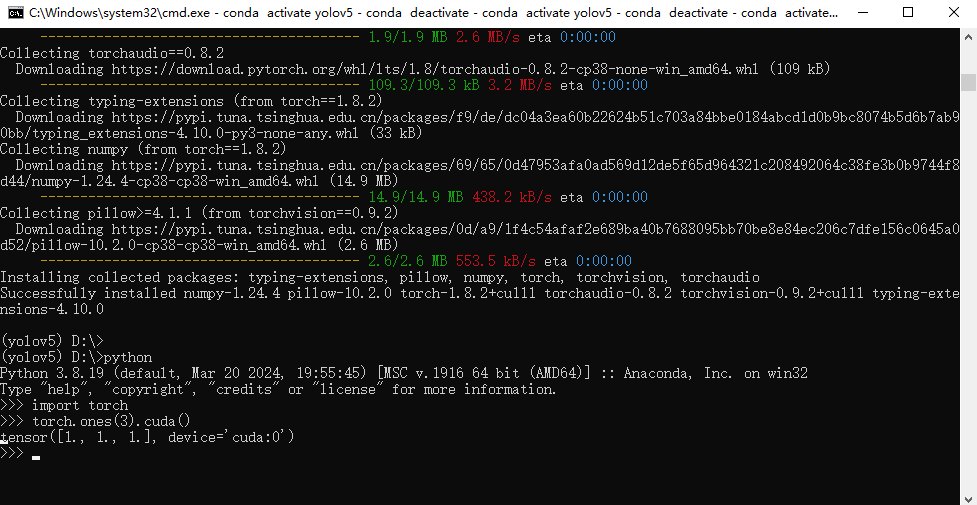
4.yolo V5
1 | https://github.com/ultralytics/yolov5 |
release中7.0版本
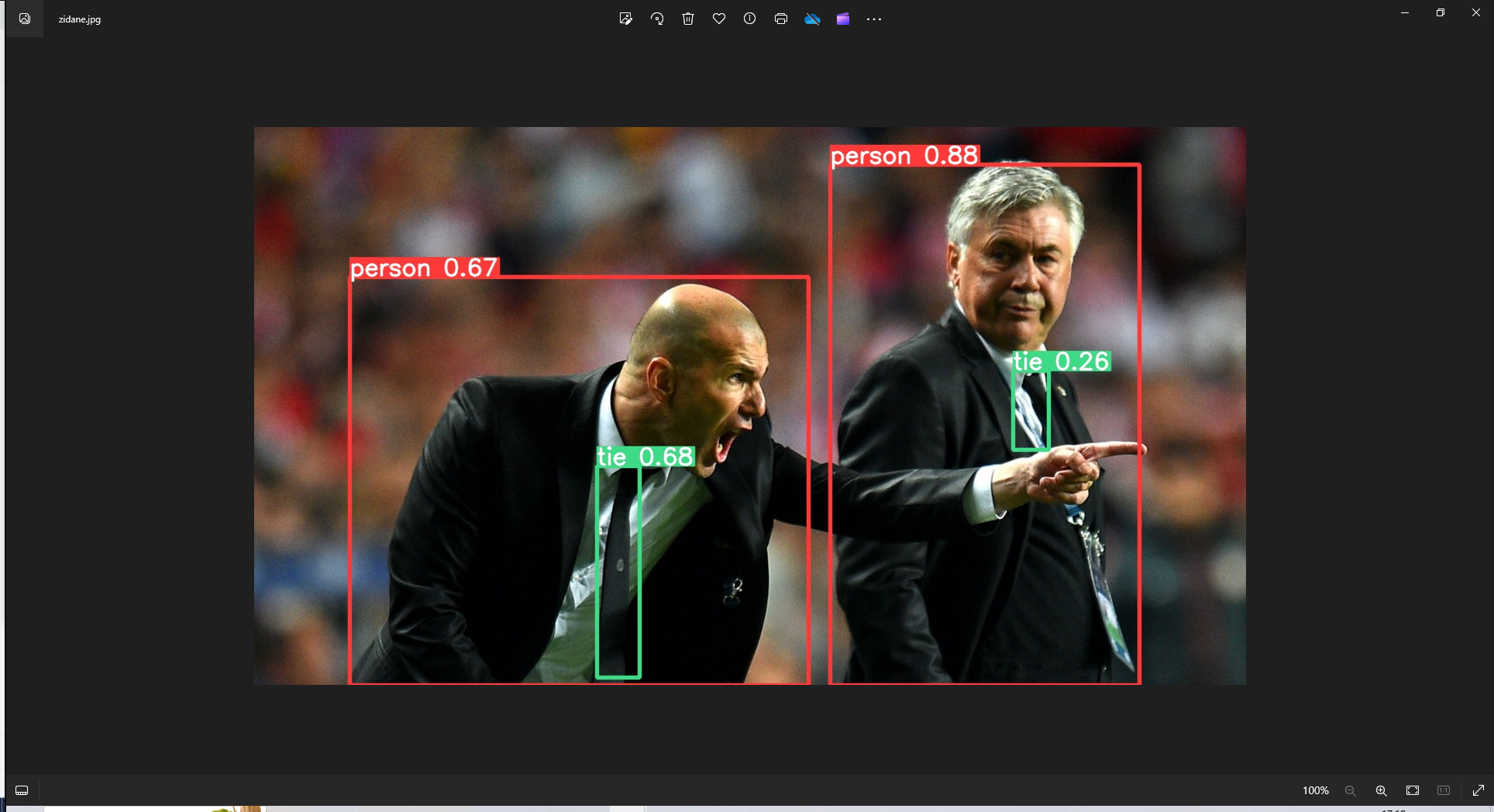
下载好源码和模型后使用样例推理如下所示,至此部署完毕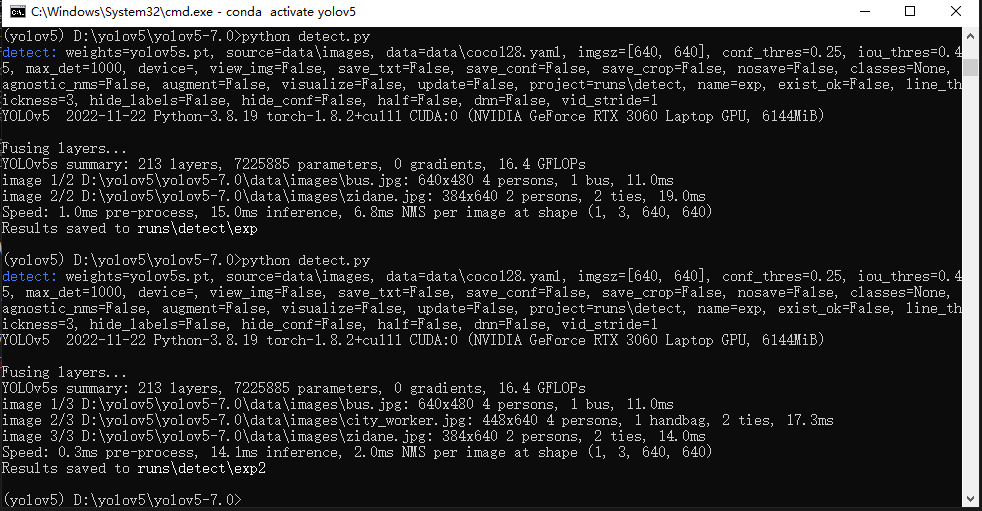
数据集构建
工作基本如下
数据采集
首先使用录屏软件录制游戏内视频,录制时游戏内建议吧准星关闭,或者只留一个点,录屏我用的obs,把视频保存到yolov5目录的datasets文件夹下,我就命名为1.mp4了。
然后先新建images文件夹,再使用getdataset.py脚本抽帧保存为图片,脚本内容如下
1 | import cv2 |
运行后images目录里大概长这样(千万记得要先新建images文件夹,不然脚本无法将抽帧图片保存)
这里我选中的前三张图片是但是录屏来回切obs和桌面时录入的,可删可不删,对后续工作没影响,我看着碍眼就删了。
手工标注
大概工作如下
![[Pasted image 20240321194100.png]]
首先安装labelimg为图片打标签工具,记得开启conda虚拟环境
1 | pip install labelimg |
然后命令行输入labelimg启动,并点击open dir选中images文件夹然后确定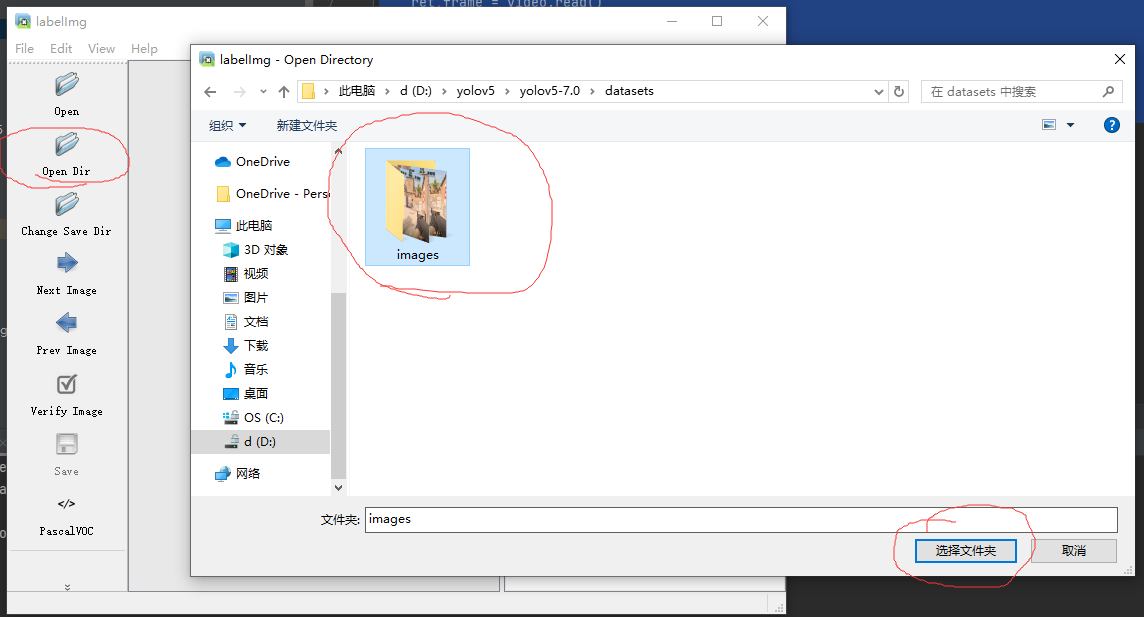
然后在images同级目录下新建labels文件夹,这个用于存放每个图片对应的标签文件,点击change save dir 然后选中刚才创建的labels文件夹,这里不放图了,跟刚才一样。
接着点击Save下面那个按钮切换保存标签格式为yolo能够读取的格式,刚开始打开应该是PascalVOC,点一次后就变成YOLO了,然后点击Save保存配置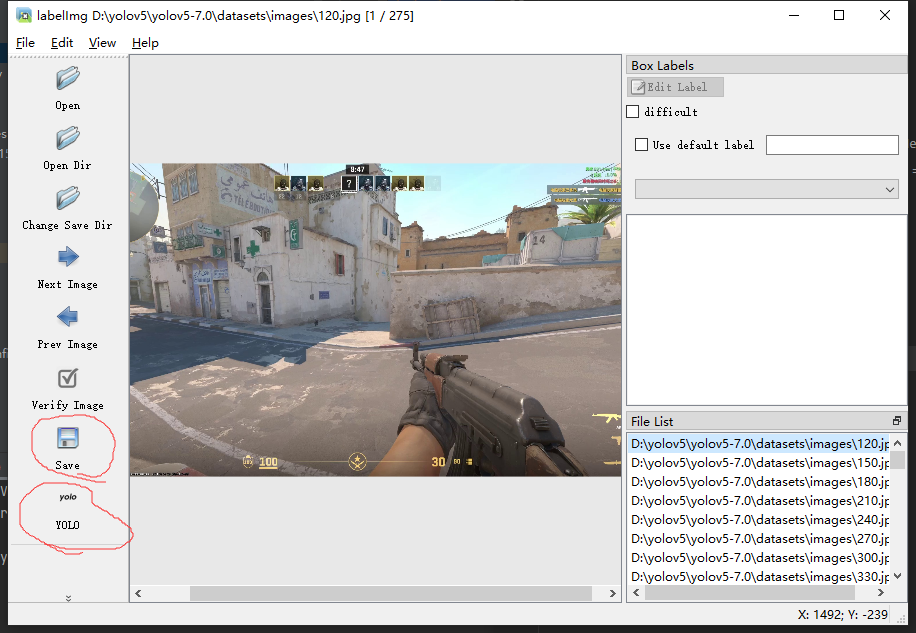
图片太多一两天标注不完需要关狄安娜哦的话可以把View里的Auto Save Mode打开,这样你下次打开就会接着上次的工作。
接下来开始标注
右键点击图片选择 create rectbox 当然它后面显示了快捷键是W,这时候鼠标变成十字,拖拽标注,我这里第一张图没有人头,所以选择下一张图片,这里也有快捷键,A是上一张,D是下一张。这里图片太小可以CTRL+滚轮调节图片缩放再标注。
拖拽完会弹出一个输入框让你输入标注的名称,对于ct和t阵营,我们考虑每方都标注头和body。
标注规则:
1.考虑到yolov5网络结构可能对于框之间的包含关系也有学习能力,head的矩形框请不要超出body矩形框。
2.标错或标歪了直接右键矩形框delete就行。
3.尸体不用标。
4.有的图片里没有需要标注的东西时就不管,直接下一张
这里我放几张示例图。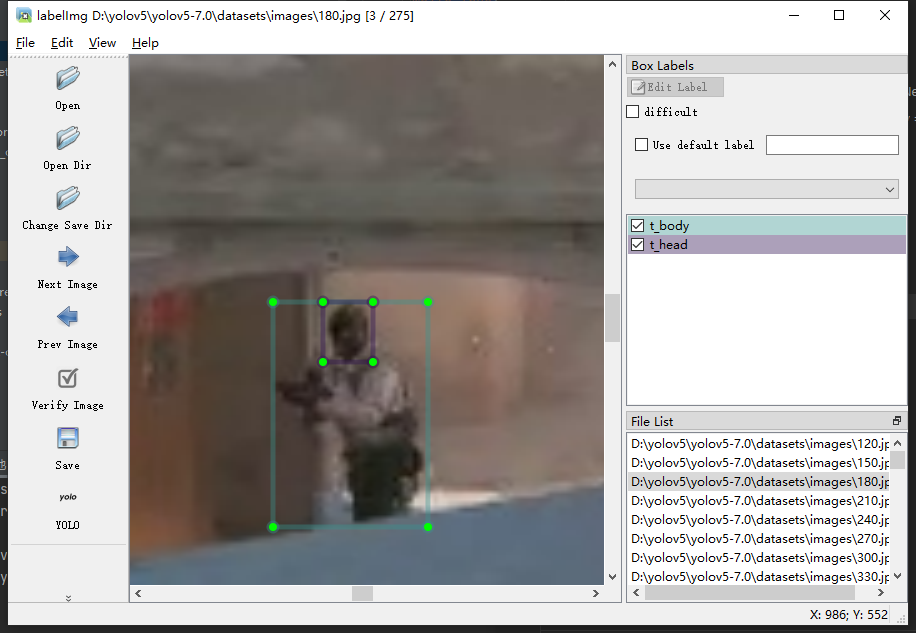
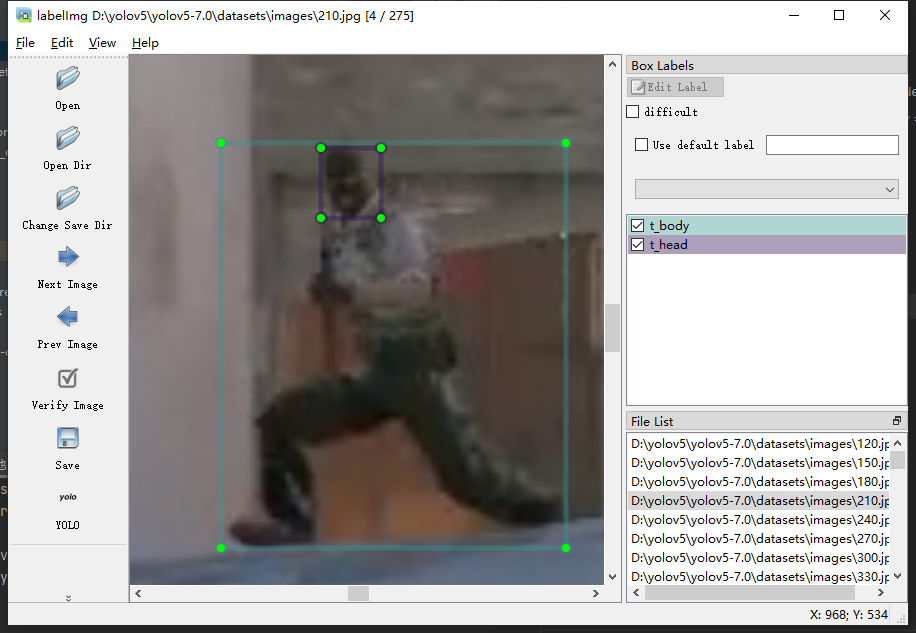
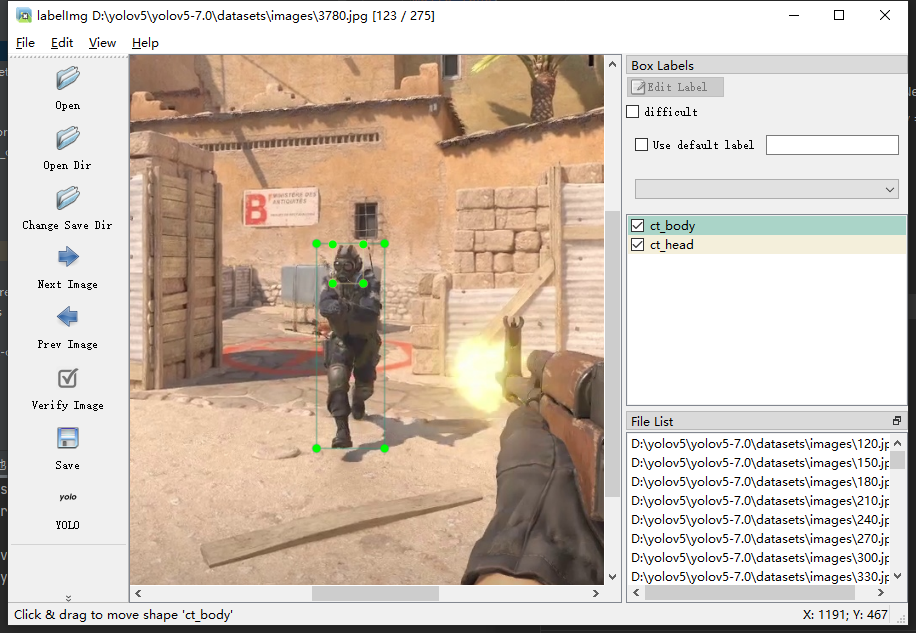
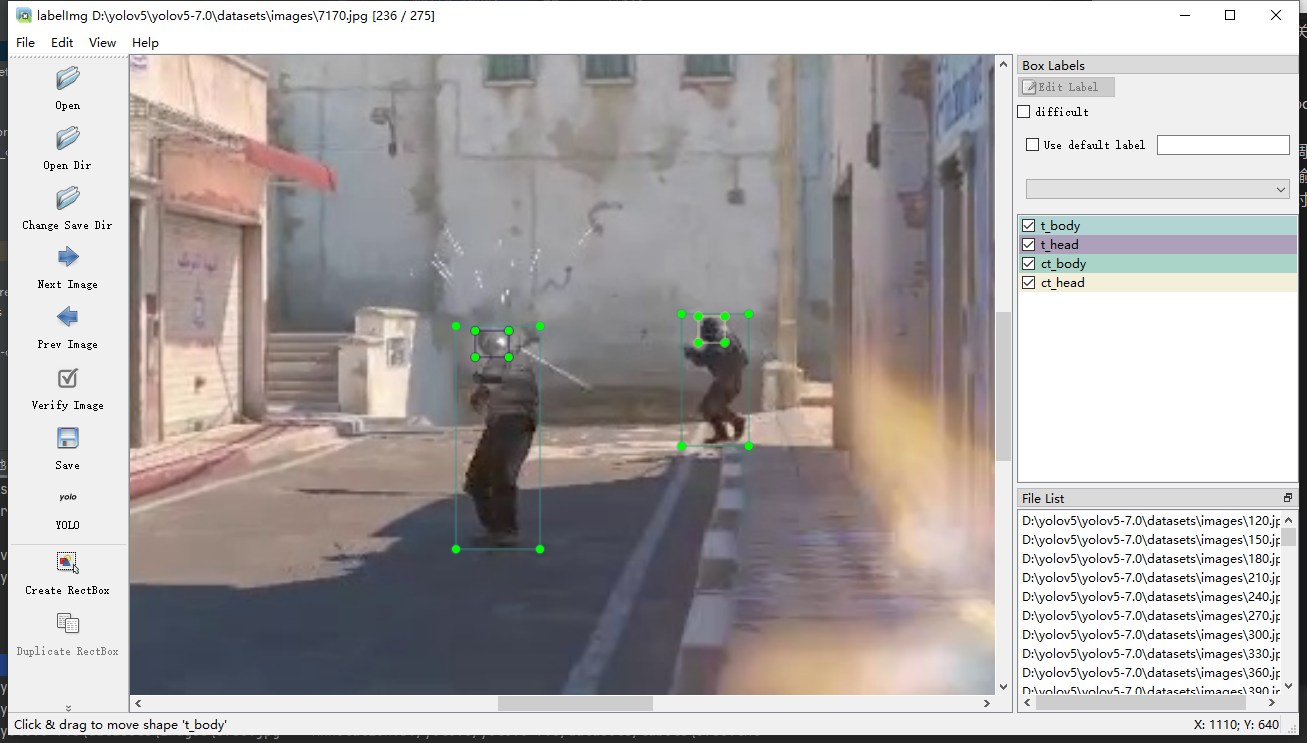
记得别标错了,所有图片标完记得检查一下,苍蝇头和悍匪有时候累了真的傻傻分不清,标完直接关闭labelimg就行了,这时候我们来看看labels文件夹有什么变化。
这里你可能注意到,有些图片没有对应的标注文件txt,那是因为那张图上你没有标注东西,这个不用管。
因为我是演示标注,所以就没标注完,只标了几张,可以看到生成了对应图片文件名的txt文件,点进去看看,这里每行是一个标注的东西,每行5个值,第一个表示这是哪个,对应到classes.txt中保存的类别中,第2到第5个值分别表示这个矩形的关键位置信息与整张图片之间的比例,比如第一行的”2 0.501302 0.543056 0.018229 0.086111”表示信息如下
类别为t_body
其余4个数值中前两个为矩形中心坐标分别在长和宽维度上在图片中的比例
后两个数分别表示矩形长度与图片长度的比例和矩形宽度与图片宽度的比例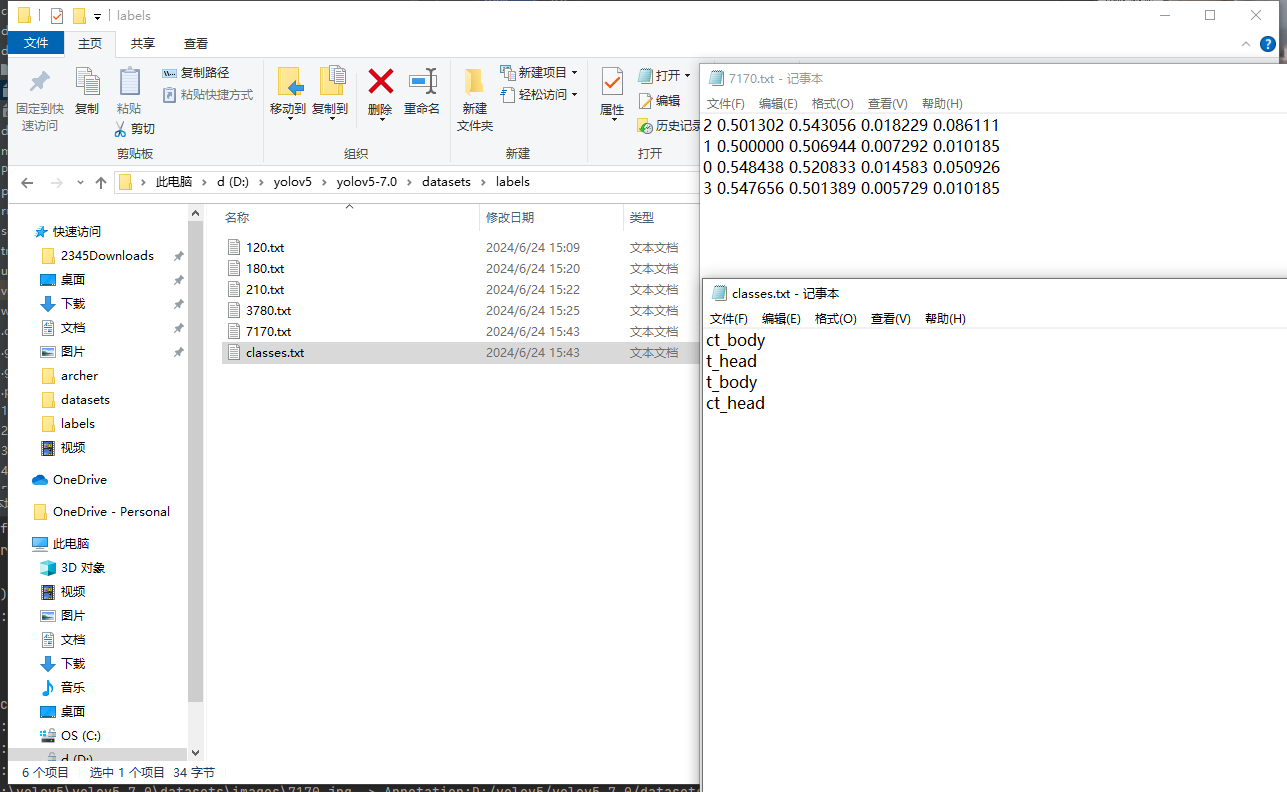
这里注意,计算机中有关于显示的坐标,无论是显示屏还是针对一张图片或一个视频,左上角坐标都是(0,0),从左到右从上到下增加,比如显示屏的像素坐标,右下角坐标为分辨率,我的是1920*1080,所以是(1920,1080)。
数据集划分
我们需要把数据划分为训练集和验证集,验证集用于验证模型性能。比例随意,9:1或10:1都行,
为此我么需要调整一下目录结构。
在images和labels文件夹内都创建train和val文件夹,并把labels文件夹下存放类别信息的classes.txt文件放到与images和labels同级。
划分的时候,由于有些图片是没有人的,所以考虑手动地选择有人的图片放到val文件夹中,其余的放到train中,对应到labels文件夹中,原本的images的val下有哪些图片,你就要把对应的标签文件放到labels的val下。
最后的images文件夹应该只有train和val这两个文件夹,没有其他任何东西,同时,上一级的datasets文件夹应该长这样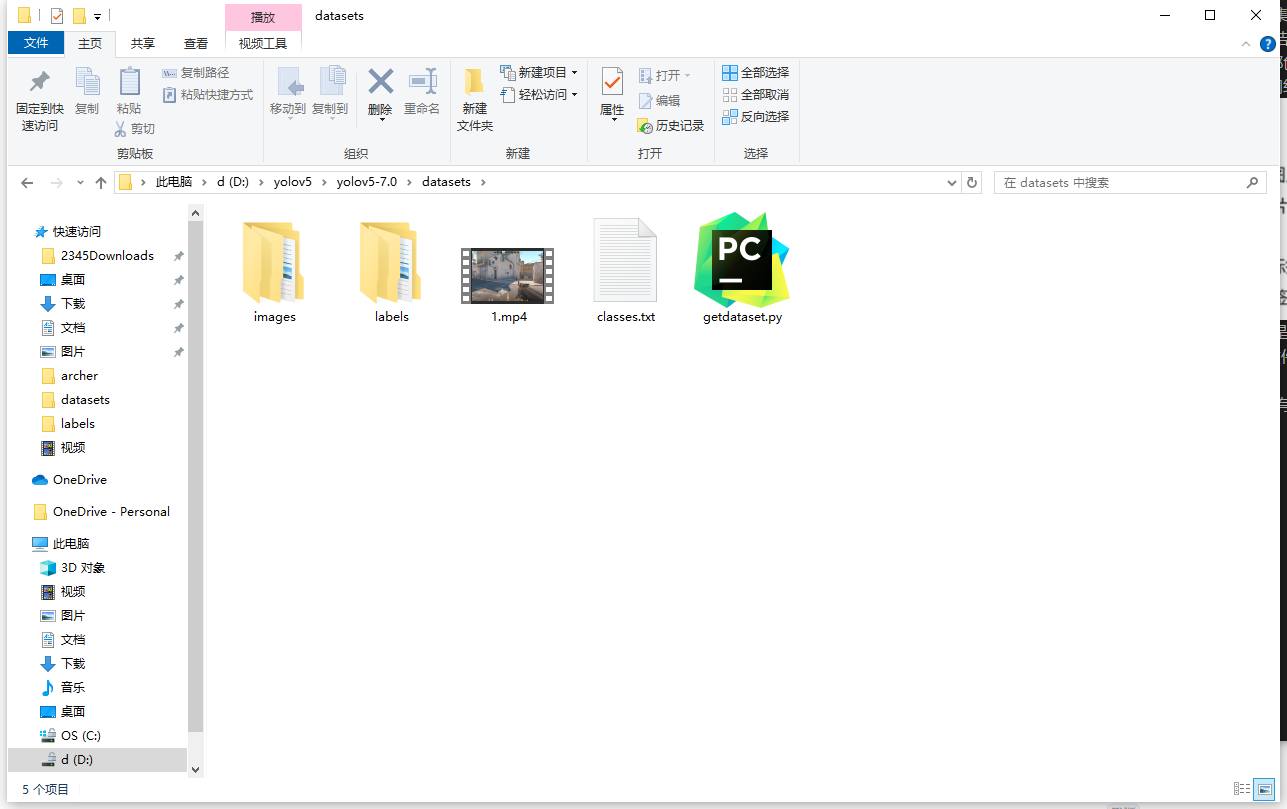
至此,数据集构建结束。
模型训练
在模型训练前,需要做出一些修改,打开yolov5文件夹下的train.py训练脚本,拖到430行左右,主要关注weighth和data这两个超参数,前者是指定预训练文件的,后者是指定数据集描述文件的。为什么需要预训练文件?这里涉及迁移学习,简单来说就是我们需要直接使用官方已训练的模型中的参数矩阵,加快收敛速度、提升模型性能。
这里将这两个参数做如下修改: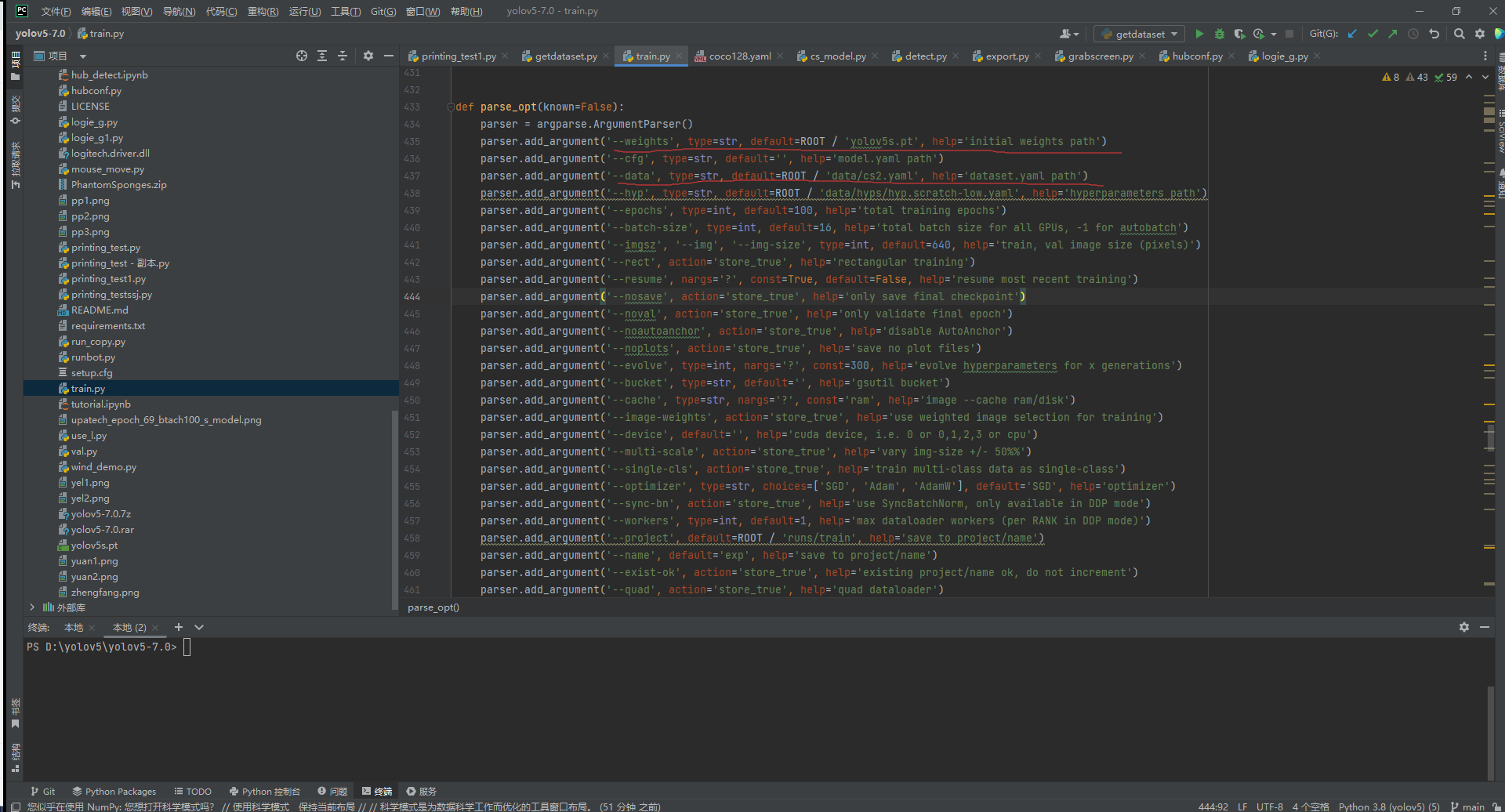
然后打开data目录下的coco128.yaml,这里我们把coco128复制一份并重命名为刚才修改的超参数data的文件名cs2.yaml,这里我详细介绍一下,各字段有什么用。
path 数据集所在目录
train 训练集图片所在目录
val 验证集图片所在目录
test 可选,测试集所在目录,这个是用于测试模型性能的。我们就不要了,直接注释掉
names 各个类别
接下来文件改成这样
这里注意,names里的顺序要与classes.txt的一致,我这里ct_body和ct_head分开的,分别是0和3,看起来别扭是因为之前使用labelimg工具标注的时候,第一张图里ct和t都有,我先标了ct的身体然后连着标了t的身体和头最后才标的ct的头,就造成个顺序,这只是看起来不爽而已,对训练和识别没有任何影响。
好了目前一切就绪,右键train.py运行,它会打印一堆控制信息,注意看一下有没有报错,常见问题如下:
1.Arial.ttf字体无法下载
开代理或手动下载放到对应位置 “~/AppData/Roaming/Ultralytics”
2.页面文件太小,无法完成操作
调整train.py中的workers超参数设置为1
修改虚拟内存,改大一点,我一个T的硬盘给分了50到100g的虚拟内存,好像用不着那么多,自己看着办吧。
3.’Upsample’object has no attribute ‘recompute_scale_factor’
pytorch版本过高导致,可选择降低版本,1.8.2目前不会报错
也可以修改pytorch源码,在报错提示信息中找到unsampling.py,删除recompute_scale_factor这个参数
等待训练完毕即可
测试模型
yolov5文件夹下run这个文件夹中会有detect和train这两个文件夹,detect用于存放模型推理的结果,train存放模型训练的结果。
根据训练好的提示信息我们找到本次训练存放结果的文件夹,大概会长这样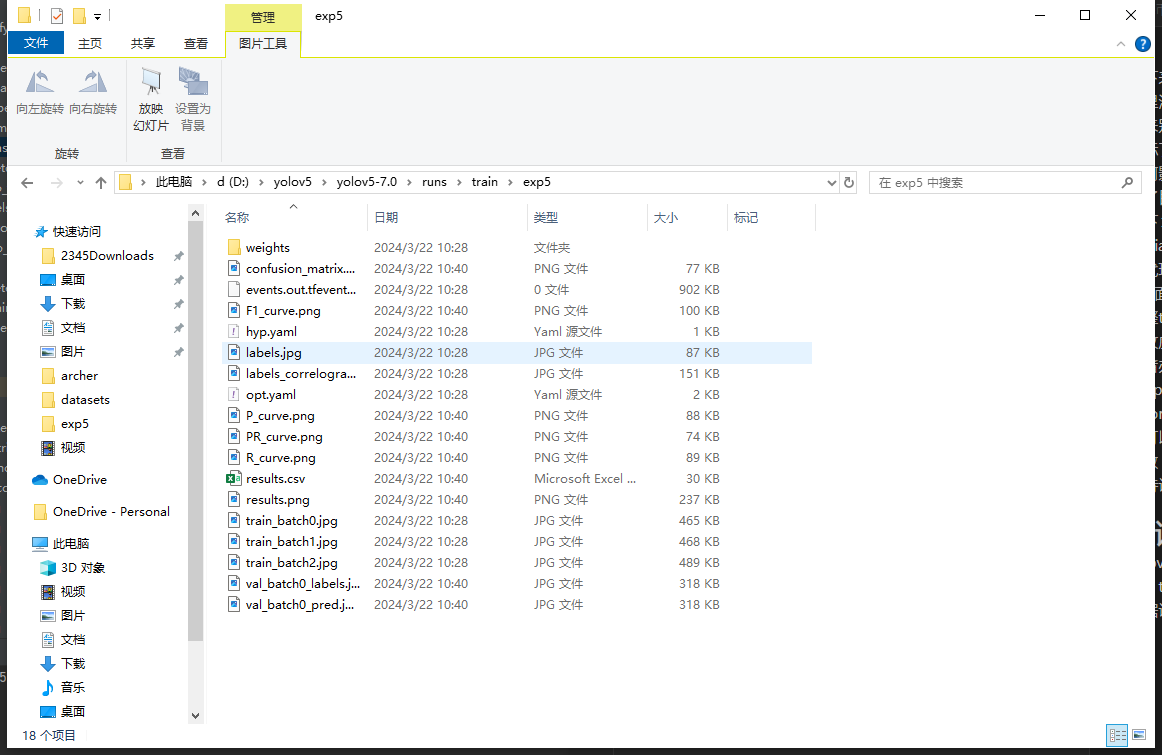
打开weights文件夹,里面存放着训练过程中效果最好的模型和最后一次训练的模型,往往最后一个会过拟合,我们选best.pt,拉到yolov5文件夹下并重命名为csmodel.pt,然后我们可以用yolov5自带的模型推理脚本detect.py来调用csmodel.pt去测试模型性能。
这里先介绍一下detect.py模型检测参数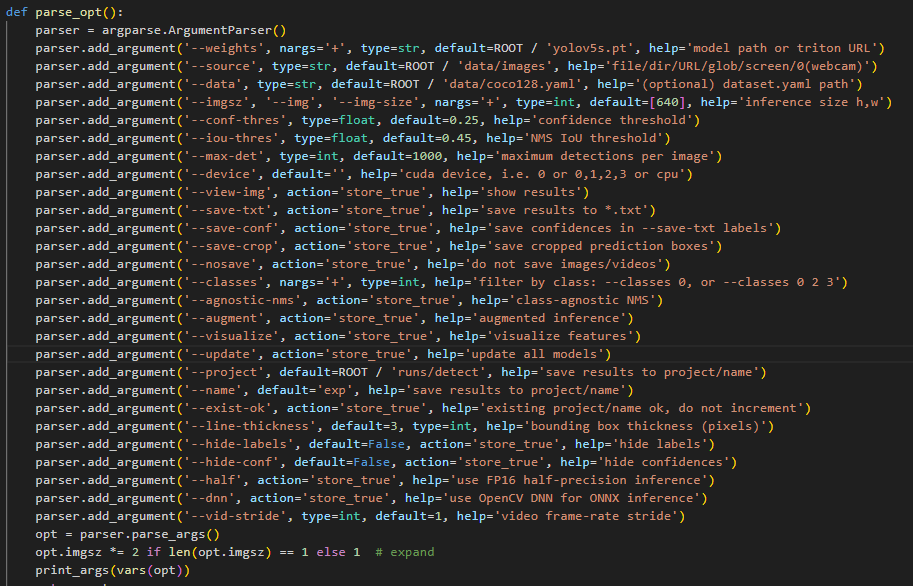
–weights
指定模型文件
1 | python detect.py --weights yolov5s.pt |
–source
指定screen时会实时地对屏幕上地内容检测
–conf-thres
置信度,只有大于置信度检测结果才会展示出来,过高过拟合、过低欠拟合,默认取值0.25
–iou-thrres
IOU阈值
交并比阈值,值越低框越少
–imgsz
图片大小
–max-det
每张图片中最大匹配数
–device
cuda设备设置一般默认
–view-img
检测结果弹窗显示
–save-txt
–save-conf
–save-crop
分别为保存result、confidences、cropped prediction boxes
–no save
不保存图片或视频
–classes
指定检测哪些类别、默认为所有类别都检测
说那么多也没用,照着我接下来的做就行
把dete.py里
–weights设置默认值为csmodel.pt 也就是你训练的模型
–data设置默认值为data/cs2.yaml 也就是之前模型训练时那么yaml
然后在pycharm命令行输入以下内容运行
1 | python detect.py --source datasets/1.mp4 --view-img |
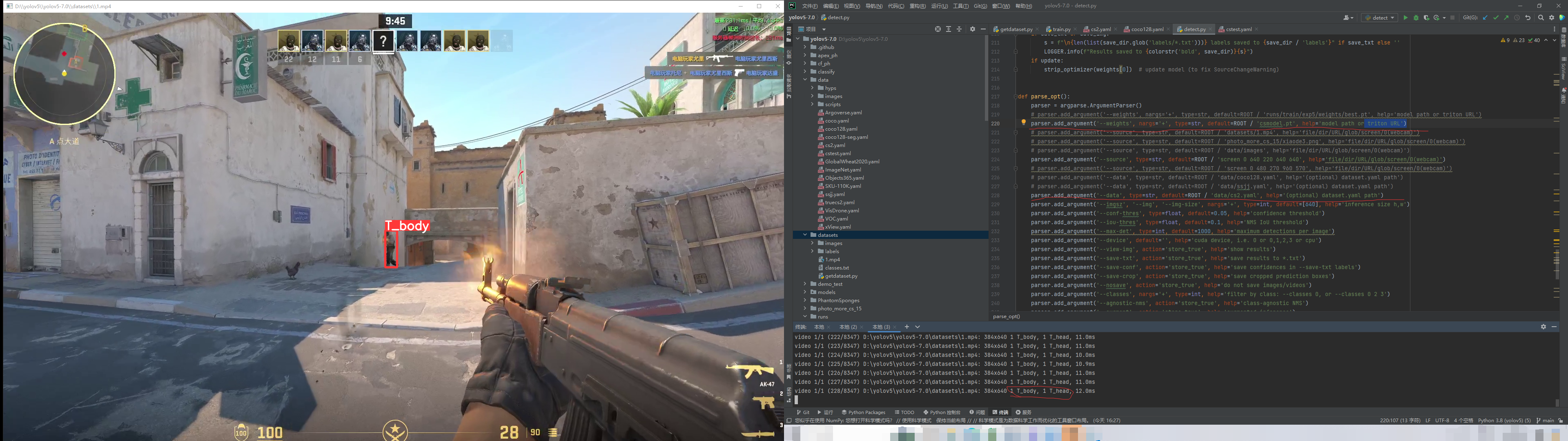
这里见谅,有些信息得打马。如果你的效果和这样类似就代表模型训练没问题了。
至此测试模型结束。


